SANA-Video: Efficient Video Generation with Block Linear Diffusion Transformer
Authors: J. Chen*, Y. Zhao*, J. Yu*, R. Chu, J. Chen, S. Yang, X. Wang, Y. Pan, D. Zhou, H. Ling, H. Liu, H. Yi, H. Zhang, M. Li, Y. Chen, H. Cai, S. Fidler, P. Luo, S. Han, E. Xie
Status: Submitted to ICLR 2026.
Preprint: arXiv: 2509.24695
Overview
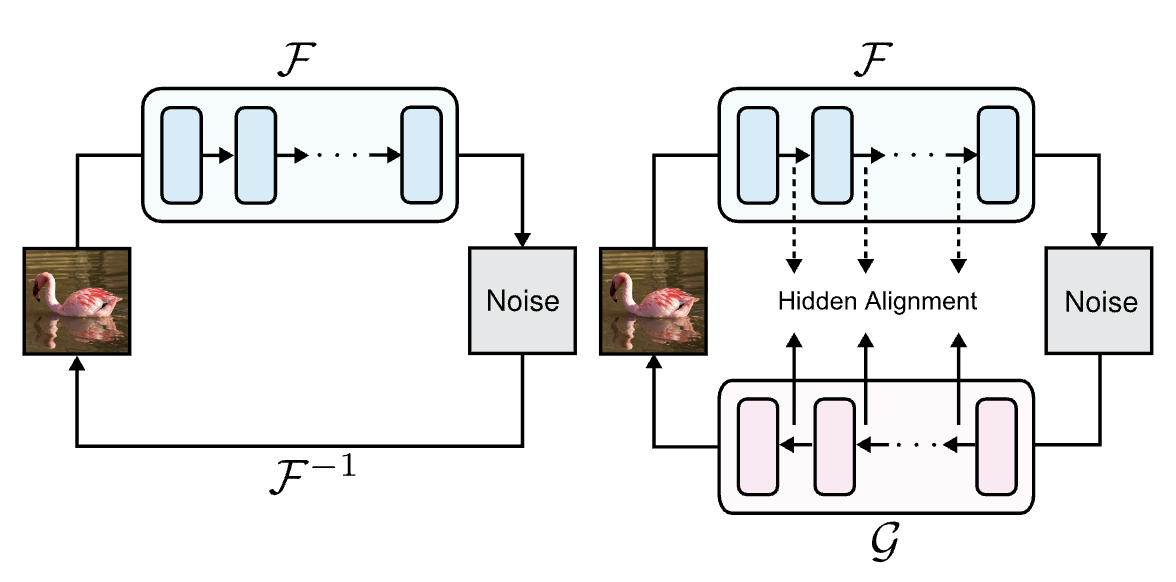
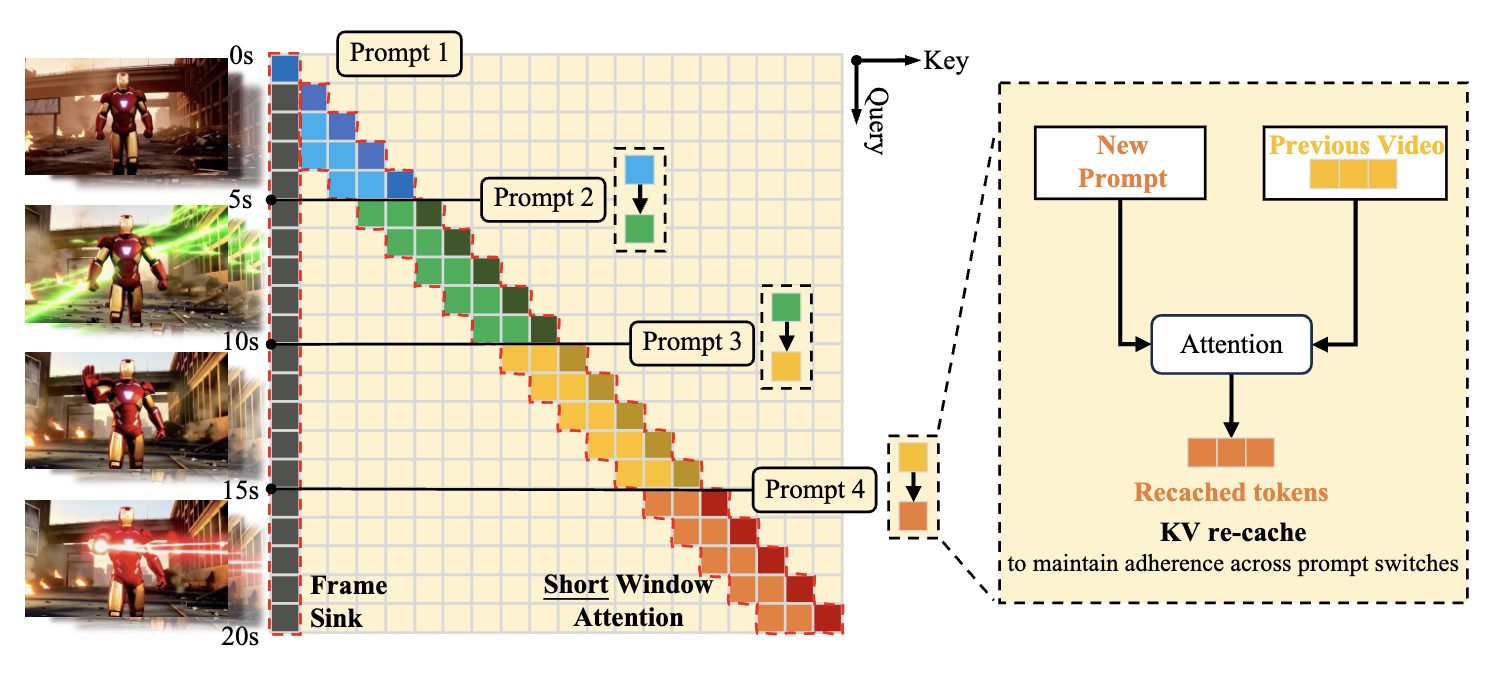
This paper introduces a highly efficient generative framework designed to break the quadratic computational bottleneck of long-duration video synthesis. To address the massive token counts inherent in high-resolution video, the authors replace standard self-attention with a Linear Diffusion Transformer (Linear DiT), reducing complexity from $O(N^2)$ to $O(N)$, and implement a Block Linear Attention with Constant-Memory KV Cache that allows for autoregressive generation of arbitrarily long sequences by maintaining a fixed-size state instead of a growing cache. Complemented by a Deep Compression Video Autoencoder (DCAE-V) that achieves a massive $32\times$ spatial compression, this architecture enables the generation of minute-long, 720p videos on consumer hardware (like the RTX 5090) with inference speeds up to $53\times$ faster than baselines like Wan2.1, all while requiring only about $1\%$ of the training compute used by large-scale models like MovieGen.