H3DP: Triply-Hierarchical Diffusion Policy for Visuomotor Learning
Authors: Y. Lu*, Y. Tian*, Z. Yuan*, X. Wang, P. Hua, Z. Xue, H. Xu
Status: Submitted to ICLR 2026.
Preprint: arXiv: 2505.07819
Overview
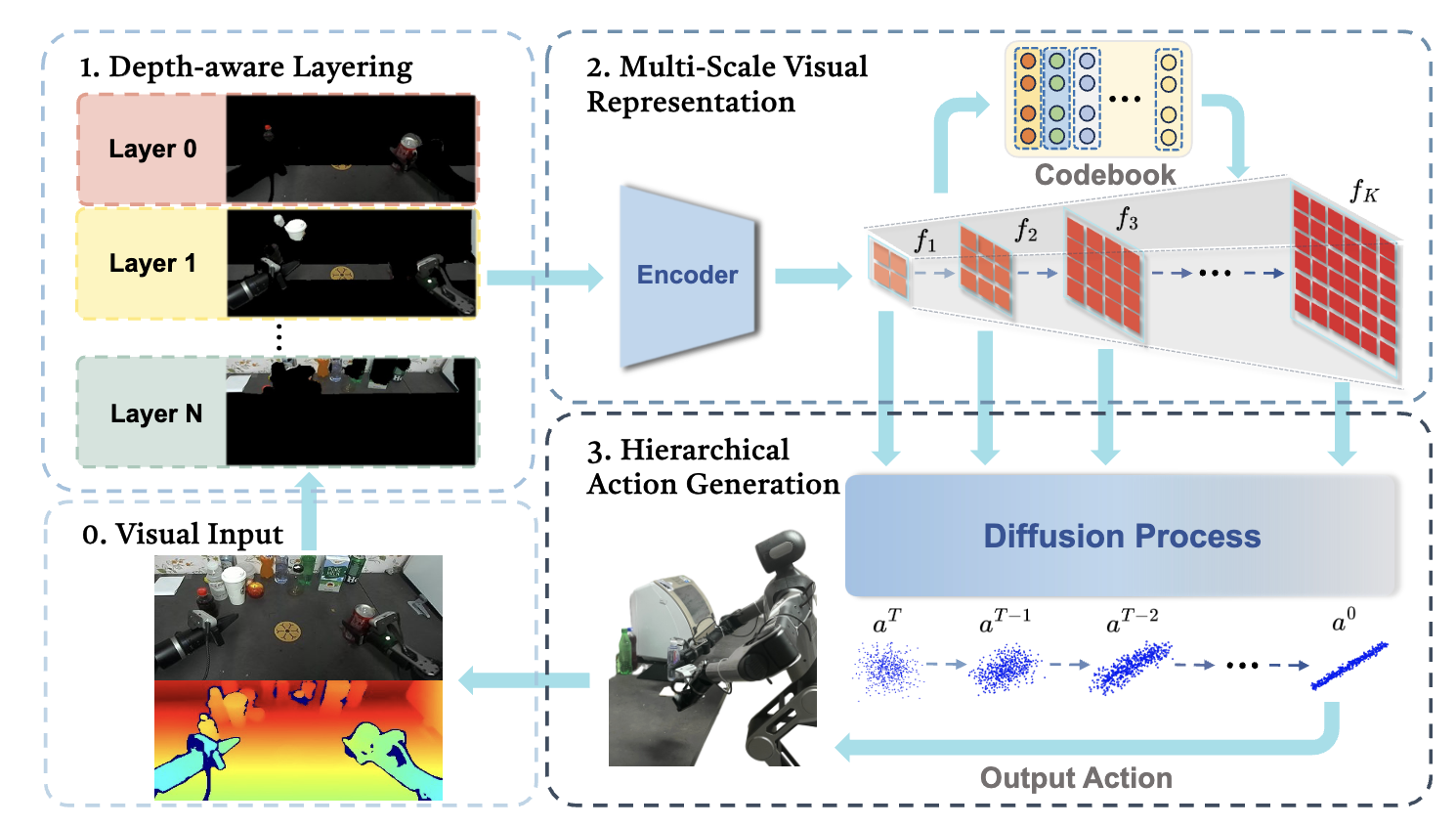
This paper proposes a novel robotic learning framework designed to tighten the coupling between visual perception and action generation through three distinct levels of hierarchy. To address the limitations of “flat” processing in existing models, H3DP introduces depth-aware input layering (organizing RGB-D data by depth to separate foreground from background), multi-scale visual representations (encoding features at varying granularities from global to local), and a hierarchically conditioned diffusion process (aligning coarse visual features with early denoising steps for global structure and fine features with later steps for detailed control). This “triply-hierarchical” design allows the model to better mimic human cognitive processing, resulting in a $+27.5\%$ performance improvement across 44 simulation tasks and superior robustness in complex, real-world bimanual manipulation scenarios compared to standard diffusion policies.